The Consumer Financial Protection Bureau (CFPB) is an independent agency of the United States government responsible for protecting consumers in the financial sector. It aims to make sure consumers are treated fairly by banks, lenders, and other financial institutions. CFPB collects and publishes a wide range of consumer financial data, which is available on its website for anyone to use, analyze, and build on. This includes consumer complaints about financial products and services such as credit cards. In this post, I use CFPB’s Consumer Complaint Database to explore public credit card complaint narratives with Python.
Imagine you’re a competitive intelligence analyst for a credit card issuer trying to make sense of the external landscape. A stakeholder wants to know what consumers are complaining about in the credit card market. That doesn’t necessarily mean they are looking for a full measure of customer experience across the market. Rather, they may be trying to identify publicly visible pain points that seem common enough to warrant closer attention. Which issues might signal competitor weakness? Which ones reflect persistent customer friction? Which ones might point to emerging risk or unmet needs that could turn into market opportunity?
This is where a public complaint source like CFPB can be useful. It doesn’t replace internal customer data, nor does it represent the full market. However, it does provide a standardized stream of public complaint narratives that can be used as an external signal. For a competitive intelligence use case, it can serve as a reasonable place to start.
The problem is that the original question is too vague to analyze directly. Which complaints count? What time period matters? What kind of answer would actually be useful? And what can a public complaint source reasonably support?
In my last post, I introduced a six-step framework on how to turn a vague business question into an analysis plan. Instead of jumping straight into the data, I will start there and use the framework to narrow the question into something specific enough to analyze.
Applying the framework
1. Capture the question as given
The original question is simple:
What are consumers complaining about in the credit card market?
It sounds reasonable, but is too broad. It does not specify which complaints should be included, what kind of answer is needed, what period to study, or what decision the analysis is supposed to support. At this stage, the goal is not to answer the question yet, but to capture it as it was asked before adding too much interpretation.
2. Identify the decision
The point here is not simply to describe complaints for their own sake. There needs to be a decision behind the analysis.
In this scenario, the stakeholder needs to decide which complaint themes deserve closer monitoring or review. A theme may be worth elevating if it points to competitor weakness, persistent customer friction, emerging risk, or an unmet need that could create an opportunity to strengthen competitive advantage.
3. Make the assumptions explicit
At this point, several assumptions are already built in:
- A public complaint source can be useful for understanding externally visible pain points in the credit card market, even if it does not represent the full market.
- Complaint narratives may reveal more specific recurring problems than broad complaint categories alone.
- Themes that are common or becoming more prominent in a public complaint channel may be useful signals for competitive monitoring.
- The analysis is meant to support prioritization and monitoring, not prove causation or measure total market incidence.
Making these assumptions explicit keeps the analysis honest about what the data can and can’t support.
4. Translate the business question into an analytical question
Once the decision and assumptions are clearer, the vague stakeholder question can be translated into something measurable:
What recurring themes appear in credit card complaint narratives, how common is each theme, and how does theme prevalence change by quarter across the selected analysis period?
This version is much more useful because it tells me what I actually need to produce. I need to identify recurring themes, measure how common they are, and compare how those themes change over time.
5. Define what a useful answer looks like
A useful answer is not just a pile of text output or a list of keywords. For this project, a useful answer would identify the main complaint themes in public credit card narratives, show how common each theme is, show which themes are becoming more or less prominent over time, and highlight which themes appear important enough to monitor as competitive signals.
This gives the analysis a finish line. If the final output does not help support this kind of answer, it probably is not the right output.
6. Constrain the scope
Only after working through the previous steps does it make sense to narrow the project. For this analysis, I constrained the scope to public CFPB credit card complaints with usable narrative text received between January 1, 2024 and December 31, 2025. I originally considered a three-year window, but the 2023 data in my export was incomplete for this project’s purposes. Rather than force an uneven time period into the analysis, I narrowed the scope to two full calendar years. Each complaint narrative was treated as one document, and theme prevalence was measured at the quarterly level.
I also kept the company field in the data to see whether issuer-specific language affected the themes, but I did not make issuer benchmarking the main objective for this analysis. I excluded non-credit card products, complaints without usable narratives, and other sources such as internal complaint logs, surveys, call-center data, or social media. I also treated causal claims as out of scope. The goal here is to identify patterns in a public complaint source, not to explain definitively why those patterns changed.
Final scope question
After working through the framework, the project became more specific:
What recurring themes appear in public CFPB credit card complaint narratives, how common is each theme, and how does theme prevalence change by quarter across 2024 and 2025?
This is a question I can actually analyze. It also sets up the rest of the workflow:
- Define the data pull
- Prepare the complaint narrative text
- Model recurring themes
- Group the modeled themes into broader reporting categories
- Summarize how the complaint mix changes over time
Data and workflow
With the question narrowed and the scope defined, the next step was to build a workflow that matched the answer I needed. I was not trying to predict outcomes or build a perfect classification system for every complaint. I just needed a practical way to identify recurring themes, measure how common they are, and track how the complaint mix changed over time.
Data source and scope
To do that, I pulled public CFPB credit card complaints with usable narrative text received between January 1, 2024 and December 31, 2025. That gave me a recent two-year window with complete calendar years and a clean quarterly comparison structure.
SQL staging and validation
I used SQL to stage the raw data, standardize key fields, and create a clean analysis-ready extract. This part of the workflow was mostly about making sure the scope I defined in the framework was actually reflected in the data. It also gave me a clear handoff into Python instead of trying to do every step in one notebook.
Text preparation
The Python workflow started with basic text cleaning. That included normalizing the narrative text, removing redaction artifacts, and creating cleaned text fields for modeling. During exploration, I also found that some complaint language was duplicated or highly templated, so I removed exact duplicate cleaned narratives before fitting the model. That step mattered because repeated complaint scripts can overwhelm the results and make certain patterns look more common than they really are.
Theme modeling and interpretation
For the theme analysis itself, I used TF-IDF (Term Frequency-Inverse Document Frequency) to turn the complaint narratives into a numeric representation based on the words and phrases they contained. In practice, this means narratives were represented by the terms that were most distinctive with the larger set of complaints. I then applied NMF (Non-negative Matrix Factorization), a topic modeling method, to identify recurring word patterns across the narratives.
Those recurring patterns became the starting point. After reviewing the top terms and example narratives for each topic, I manually labeled the themes and grouped weaker or more issuer-specific themes into broader reporting categories that were easier to interpret.
This step was important because the raw model output did not automatically translate into a useful business answer. Some topics mapped cleanly to recognizable complaint issues, while others reflected issuer-specific language, legal boilerplate, and repeated complaint scripts. Reviewing and grouping the themes made it easier to separate the stronger complaint patterns from the noisier ones and to summarize the result in a way that better matched the original question.
What the model surfaced
A small number of complaint groups carried most of the signal
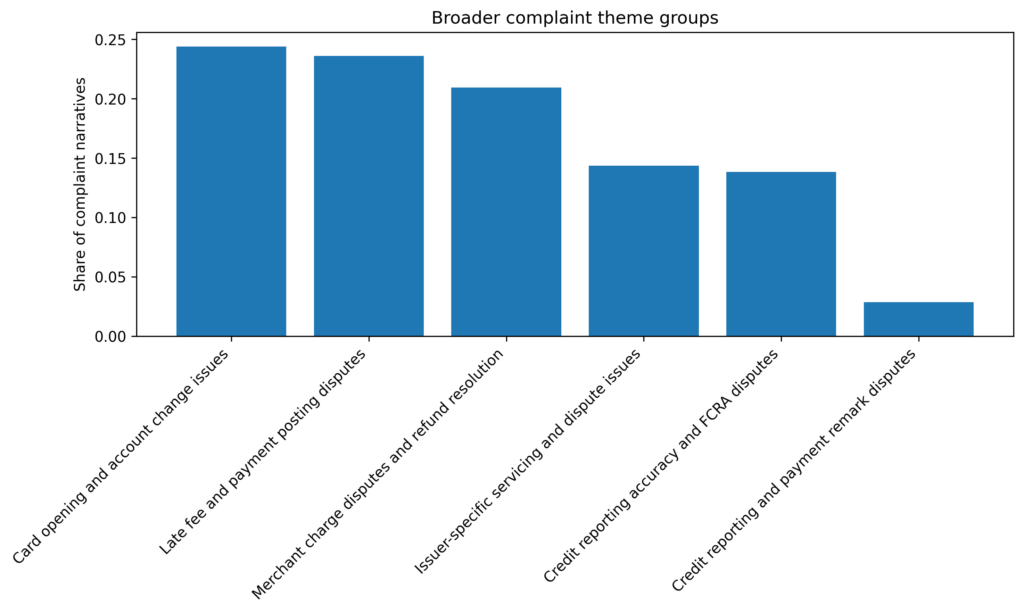
After reviewing the model output and grouping the weaker or more issuer-specific topics into broader reporting categories, six higher-level complaint groups remained.
The largest group was card opening and account change issues, which accounted for 24.4% of the deduplicated modeling set. This group included complaints about cards being opened without clear consent, account conversions consumers did not expect, and confusion around replacement cards, inactive cards, or account closures. Close behind it was late fee and payment posting disputes at 23.6%, followed by merchant charge disputes and refund resolution at 20.9%. Together, those three groups made up 68.9% of the complaint narratives used in the final theme model.
Two other groups were still meaningful, but less dominant. Issuer-specific servicing and dispute issues represented 14.4% of the modeled complaints, while credit reporting accuracy and FCRA disputes accounted for 13.9%. A smaller group, credit reporting and payment remark disputes, represented 2.9% of the modelling set and appeared more template-driven than the larger categories, so I treated that one more cautiously in interpretation.
The strongest groups were not all equally clean
Some reporting groups translated more cleanly from the model than others.
The clearest groups were the ones centered on late fee and payment posting disputes, merchant charge disputes and refund resolution, and credit reporting accuracy and FCRA disputes. These themes were relatively consistent when I reviewed the top terms alongside the strongest example narratives. In those cases, the model output aligned reasonably well with recognizable complaint issues.
Other topics were less clean. Several themes were shaped partly by issuer-specific language, and some complaint clusters appeared to reflect repeated or highly templated complaint scripts. Exact duplicate cleaned narratives were removed before fitting the final model, but near-duplicate variations still appeared in some topics. This did not make the patterns useless, but it did mean the raw model output needed to be interpreted rather than taken at face value.
The complaint mix changed over time
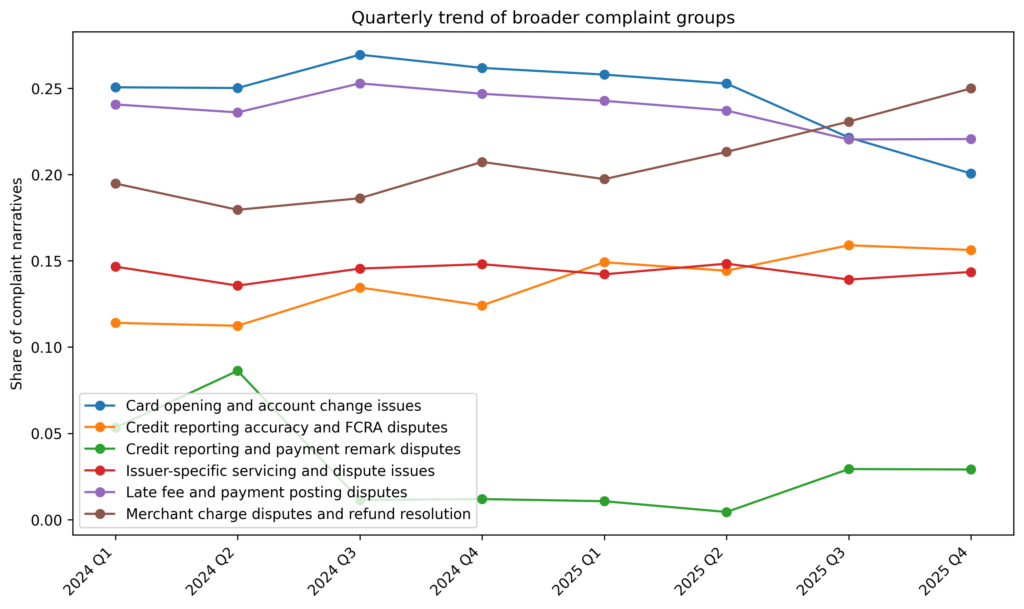
Looking only at overall theme size would miss one of the more useful results. The more interesting pattern showed up when I compared theme prevalence by quarter.
From 2024 Q1 to 2025 Q4, the complaint mix shifted in a noticeable way. Merchant charge disputes and refund resolution showed the largest increase, rising from 19.5% of complaint narratives in 2024 Q1 to 25.0% in 2025 Q1, an increase of 5.5 percentage points. Credit reporting accuracy and FCRA disputes also became more prominent, increasing from 11.4% to 15.6%, or 4.2 percentage points.
At the same time, card opening and account change issues declined from 25.1% in 2024 Q1 to 20.1% in 2025 Q4, a drop of 5.0 percentage points. Late fee and payment posting disputes remained one of the largest groups throughout the period, but declined more modestly, from 24.1% to 22.1%. Issuer-specific servicing and dispute issues were relatively stable over time.
What the findings suggest through the four lenses
Taken on their own, these shifts describe the complaint mix. Interpreted through the original framing, they also suggest which themes look more like persistent friction, which look more like emerging risk, and which may point to competitor weakness or unmet needs.
Persistent friction
Late fee and payment posting disputes remained one of the largest complaint groups throughout the period. Even with a modest decline, they stayed large enough to suggest a recurring operational friction point rather than a short-lived spike. That makes them important not because they are rising the fastest, but because they remain stubbornly present.
Emerging risk
The clearest emerging signals were merchant charge disputes and refund resolution and credit reporting accuracy and FCRA disputes. Both became more prominent over the period, and the increase in merchant dispute and refund issues was especially noticeable. In a competitive monitoring context, those are the themes I would treat as the strongest candidates for closer watch.
Competitor weakness
Card opening and account change issues were the largest group at the start of the period, even though they declined over time. That suggests this was a meaningful public pain point in the complaint mix, but one that became less dominant relative to merchant disputes and credit reporting issues by the end of the period. I would not treat the decline itself as the story. I would treat the underlying issue family as evidence that account opening, card conversion, and related change-management processes were important enough to have surfaced strongly in public complaints.
Unmet needs
Some complaint groups point less to isolated service failures and more to gaps in how consumers expect disputes, refunds, payments, and account corrections to work. That does not prove a specific product opportunity. Though, it does suggest areas where clearer processes, stronger communication, or better experience design could matter.
What I’d tell the stakeholder
I would not say that this analysis shows everything consumers are experiencing in the credit card market. I would say something narrower and more useful.
Within this public complaint source, the complaint mix over the period appears to be shifting toward merchant charge and refund disputes and credit reporting accuracy disputes, while late fee and payment posting issues remain a large source of recurring friction. Card opening and account change issues were still important, but they were less prominent by the end of the period than they were at the beginning.
If the goal is competitive monitoring, that points to three practical takeaways. First, merchant dispute and refund problems look like the clearest emerging signal. Second, credit reporting accuracy issues also deserve closer attention because they increased and touch a more sensitive reporting and compliance area. Third, payment posting and late fee complaints remain large enough to treat as an ongoing friction point rather than a background issue.
That is a much more useful answer than simply saying, “Here are the complaints.”
What I’d watch next
The next thing I would watch is whether the increase in merchant charge disputes and refund resolution continues, levels off, or reverses in later periods. I would also watch whether credit reporting accuracy and FCRA disputes continue rising alongside them.
For the more stable complaint groups, especially late fee and payment posting disputes, the question is less about short-term change and more about whether they remain persistently large enough to treat as a standing friction point.
I would also want to refine the weaker parts of the workflow in a later iteration. Exact duplicates were removed, but near-duplicate complaint scripts still remained. A few model-generated topics were also shaped partly by issuer-specific vocabulary. So, if I continued this work, I would want to separate broader market patterns from issuer-driven or template-driven language more cleanly.
Limitations
This is a public complaint signal, not a full market view
The first limitation is the data source itself. CFPB complaint narratives are a public complaint channel, not a complete measure of customer experience in the credit card market. They reflect the subset of customers who chose to file a complaint, and only the narratives that were published and available for analysis. That makes the data useful as an external signal, but not as a census of all credit card problems.
For that reason, the results should be read as patterns within a public complaint source, not as estimates of total market incidence.
Complaint narratives are messy and not fully standardized
Even after cleaning, the complaint narratives were not a perfectly uniform text source. Some complaints included legal boilerplate, issuer-specific language, or repeated template-style phrasing. Exact duplicate cleaned narratives were removed before fitting the final model, but near-duplicate versions still remained. That means some themes were shaped not only by underlying complaint issues, but also by the way certain complaints were written and repeated.
This mattered most for the smaller reporting-related themes, which appeared more template-driven than the larger complaint groups.
Topic models do not produce finished business categories on their own
The model output was only a starting point. TF-IDF and NMF can identify recurring word patterns, but they do not automatically produce clean business-ready themes. Some topics mapped well to recognizable complaint issues, while others reflected noisier combinations of issuer names, legal references, and servicing language.
That is why manual review was necessary. I used top terms and example narratives to label the themes, then grouped weaker or more issuer-specific topics into broader reporting categories. Those groupings were analytically useful, but they were still interpretation decisions, not objective truth.
The results describe pattern shifts, not causes
The trend analysis showed that some complaint groups became more or less prominent between 2024 Q1 and 2025 Q4. However, those changes do not explain themselves. This analysis does not show why merchant charge disputes increased, why card opening and account change issues declined, or what underlying business, regulatory, or consumer behavior changes may have contributed to those shifts.
The results support monitoring and prioritization. They do not support causal claims.
Issuer names sometimes influenced themes
A few model-generated topics were shaped partly by issuer-specific vocabulary rather than one clean complaint issue. Instead of forcing those themes into overly precise labels, I grouped them into a broader issuer-specific servicing category. That made the final reporting groups easier to interpret, but it also means the modeling results should be read as a practical summary than a perfect taxonomy of complaint behavior.
What the results do support
Even with those limitations, the analysis still supports a narrower and more defensible conclusion than the original vague question. It shows which complaint patterns were most prominent with this public complaint source, which ones dominated the complaint mix, and which ones became more or less prominent over time. For an external monitoring use case, that is still useful. It helps separate broad market noise from the complaint patterns that seem most worth watching more closely.
The takeaway
The original question behind this project was simple:
What are consumers complaining about in the credit card market?
On its own, that question was too broad to answer well. It did not define what source to use, what time period mattered, what kind of output would be useful, or what decision the analysis was meant to support. That is why I started with the framing step instead of jumping straight into the data.
Once the question was narrowed, the project became much more manageable. Using public CFPB credit card complaint narratives from 2024 through 2025, I was able to identify a small number of broader complaint groups, measure how common they were, and track how the complaint mix shifted over time. The strongest movement in this complain source was away from card opening and account change issues and toward merchant charge/refund disputes and credit reporting accuracy disputes.
That does not tell us everything about the credit card market, nor does it explain why those shifts happened, but it does produce a more useful answer than the original vague question. It shows which complaint patterns stood out in a public complaint channel, which ones dominated the mix, and which ones became more or less prominent over the period analyzed.
For this kind of project, that is really the point. The hard part is not just running Python on a text dataset. It is turning a loose business question into something specific enough to analyze and honest enough to interpret. Once the question is framed clearly, the workflow becomes much easier to defend.
Project repository
If you want to follow the full workflow, the project repository is available on GitHub. It includes the SQL staging layer, the Python setup and text preparation notebooks, the topic modeling notebook, and the final tables and figures used in the analysis.
Repository: github.com/tivonio/python-cfpb-complaint-nlp
Pingback: Why Analytics Still Requires Judgment - tivon.io